When making the most common form of deepfake, the face-swap video, the goal is to replace a “target face” with a “source face.” This gives the impression that the person the creator selects (the source face) was in fact performing the action depicted in the target person’s video. Below, we see the source face of Nicolas Cage appearing in a variety of major films.
In order to make a highly convincing face-swap, the creator first needs a “trained model” to make the swap, which involves algorithms processing a large dataset of images related to each person’s face. The algorithms “learn” a wide range of facial features (eyes, ears, hair, etc.) as well as an equally wide range of particular qualities (tones, textures, etc.). The result is a trained model that not only possesses a detailed and inclusive understanding of the features of a human face (knowledge of where an eye, ear, etc. should be positioned), but an understanding of these particular faces.
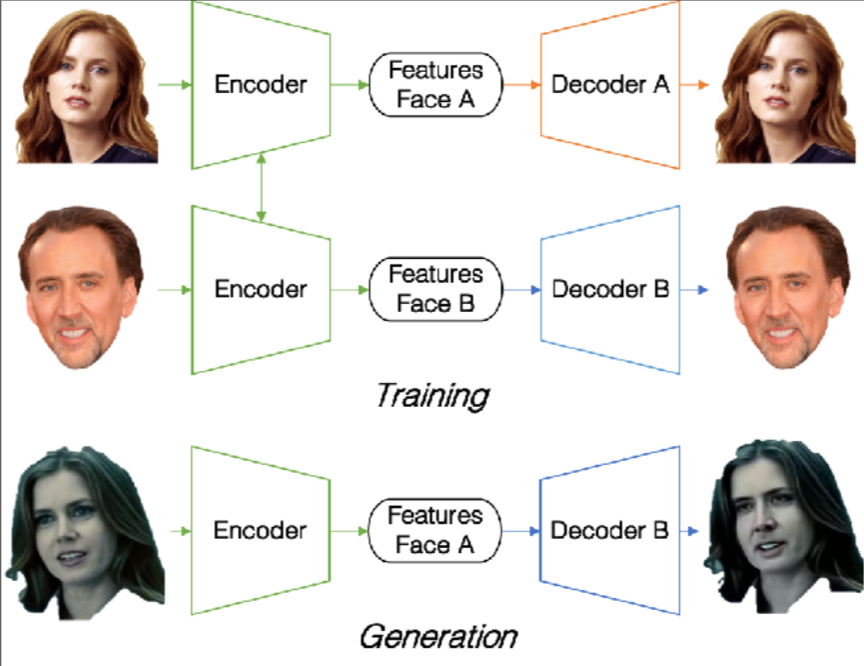
Drawing on the training data, the model begins a frame-by-frame reconstruction of the source person’s face in the context of the target person’s video. The person in the video retains the expressions, mannerisms and words of the target individual, but the facial features of the source—the person that the viewer is supposed to think is performing the action.
As a final step, post-production effects may be applied to the deepfake, to ensure that the movements of the head and neck look smooth and convincing.
References Text from Joshua Glick, “Deepfakes 101,” In Event of Moon Disaster project website, MIT Center for Advanced Virtuality, 2020. Video, “Nicolas Cage, Mega Mix Two, Derpfakes,” Feb 2, 2019, YouTube. Celebrity encoder/decoder image from David Guera Edward J. Delp, “Deepfake Video Detection Using Recurrent Neural Networks,” Purdue University, 2018. Background theme image from Shutterstock.